Introducing the Scale of Flawed Science

An updated hierarchy of evidence for the age of memes, rumors, and AI hallucinations
I’ve been dissecting science rumors and flawed studies for five years now, and there is one communication challenge that I have run into over and over again.
For any given scientific claim or study, it's easy to say "this is flawed," and explain why. What's much more difficult is to explain just how flawed it is. On a scale of "this is a decent study but has some understandable flaws and is being taken out of context" to "this defies the laws of physics," where does this particular scientific claim land?
This also creates a trust problem. When all of scientific criticism sounds the same ("it's flawed!"), it can create the perception that scientists don't discriminate between a blog post and a peer reviewed meta-analysis in their level of criticism.
The hierarchy of evidence falls short in the age of memes
The hierarchy of evidence is supposed to help us with this communication challenge. This pyramid provides a general guideline on what types of evidence are considered more or less reliable – case reports of a single patient are less reliable than cross-sectional observational studies of many patients, which are less reliable than randomized controlled trials.
But in a world of fraud, questionable peer-review, social media screenshots, and viral unverified claims, this hierarchy falls short. Where does "this meta-analysis was skewed by a randomized trial that used fraudulent data" go on this chart?

We need a better scale
To help solve this communication challenge, I’m borrowing an idea from my favorite weather website. During my MD/PhD training I lived in the flood zone known as Houston, Texas. Because Houstonians have lived through so many horrible floods (for me it was the Tax Day Floods, Memorial Day Floods, Hurricane Harvey, Tropical Storm Imelda), it’s very easy to get stressed out when heavy rain is in the forecast.
Space City Weather is a local weather blog beloved by the entire city because it aims to inform, not freak people out. They helped address this communication challenge by providing an unofficial Flood Scale that distills the complexity of weather forecasting down to a simple “how bad is it gonna to be.” As a non-meteorologist, this is deeply appreciated.

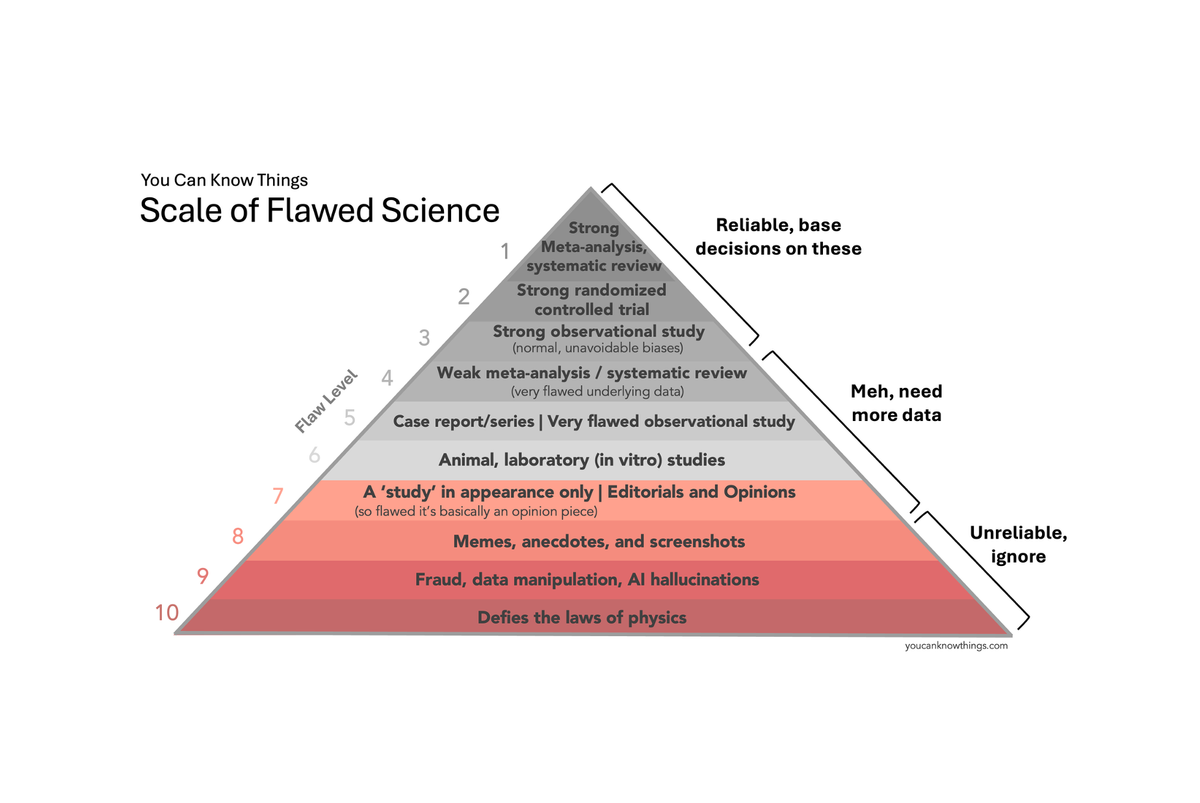
The Scale of Flawed Science
Inspired by the Space City Weather Flood Scale, I have decided to create a You Can Know Things Scale of Flawed Science. It’s not a replacement for the evidence pyramid taught in medical school, but a simplified tool to help the public better understand the quality of scientific evidence. Ultimately, what we care about is whether sources gives us reliable information that we can use to make medical decisions. So for each level, we'll answer that question.
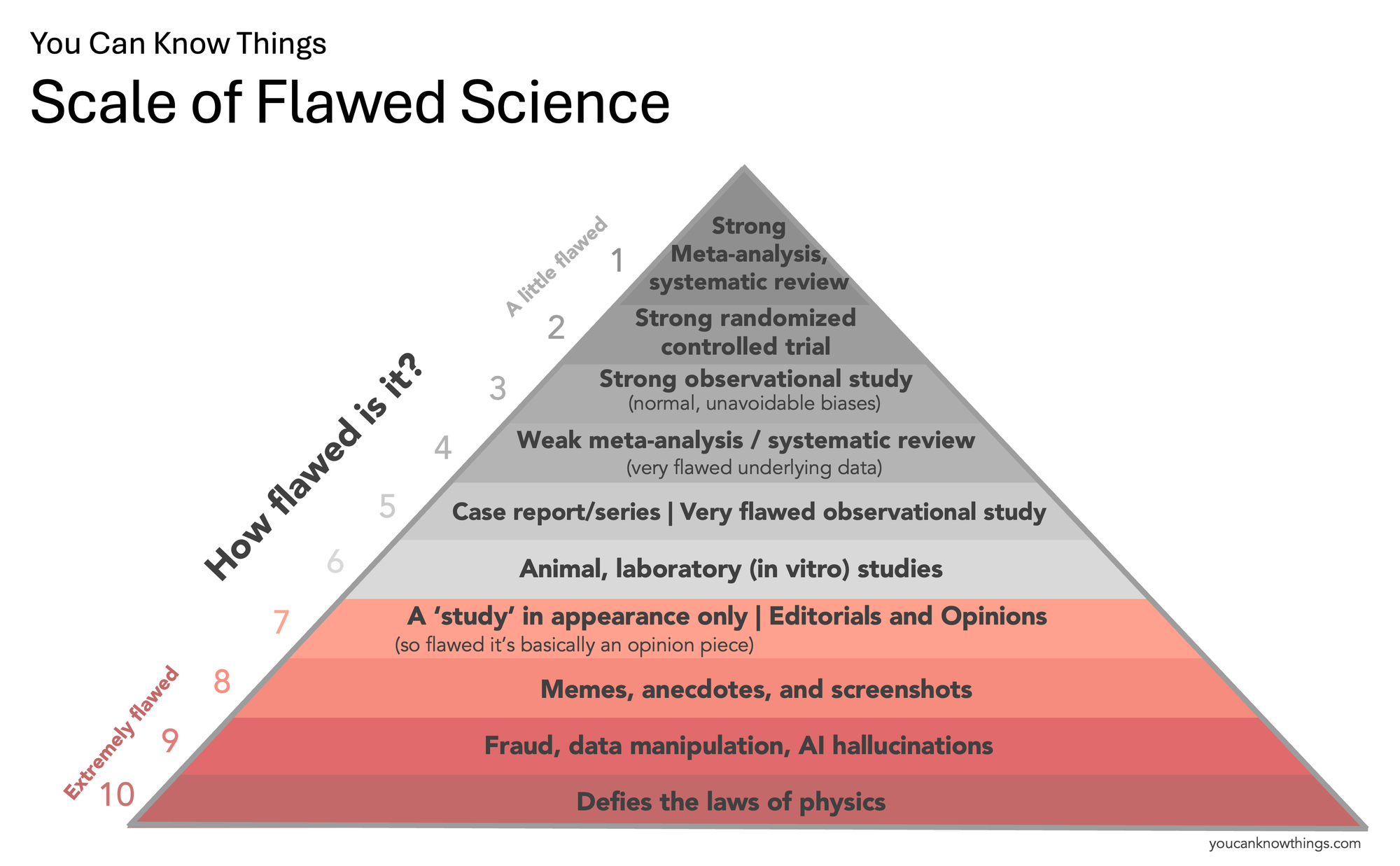
Note there is no level for "zero flaws" on this scale – you can always find some weakness or limitation in even the best study. Science is a messy, imperfect process, and this is normal. The trick is distinguishing studies that have these "normal" kinds of flaws from the truly abysmal ones. That's what this scale aims to do.
Let's start at the bottom.
Flaw Level 10: Defies the laws of physics.
These are scientific claims that can be dismissed immediately, because they contradict very basic rules of physics, chemistry, or biology. This is personally my favorite category, because the claims are always pretty funny to read. Examples include this now retracted study claiming 5G radiation causes viruses to spontaneously generate inside our cells by poking very small holes in us or this claim that a firefly protein could be used to sneakily track humans (by making us glow?)
Does this type of information give us reliable information we can use to make medical decisions? No, it is wrong.
Flaw Level 9: Fraud, data manipulation, and AI hallucinations.
These are scientific claims based on data that has been faked or manipulated, either by accident or on purpose, to the point where they no longer reflect a true search for answers. Examples include this implausibly large study that claimed hydroxychloroquine increases mortality in COVID patients that was retracted when no one could verify the data, and sections of the recent MAHA report which contained fake citations likely hallucinated by a chatbot. Data manipulation and p-hacking don’t outright fabricate data, but instead slice and dice real data in multiple ways until a desired result appears, often leading to findings that aren’t true or reproducible. A likely example includes this COVID vaccine analysis which had five earlier unpublished versions showing the opposite result of what was eventually published. A special note here for paper mills, which are low quality journals that will publish nearly anything for a small fee, and often publish fraudulent or manipulated data.
Does this type of information give us reliable information we can use to make medical decisions? No, it is made up or manipulated.
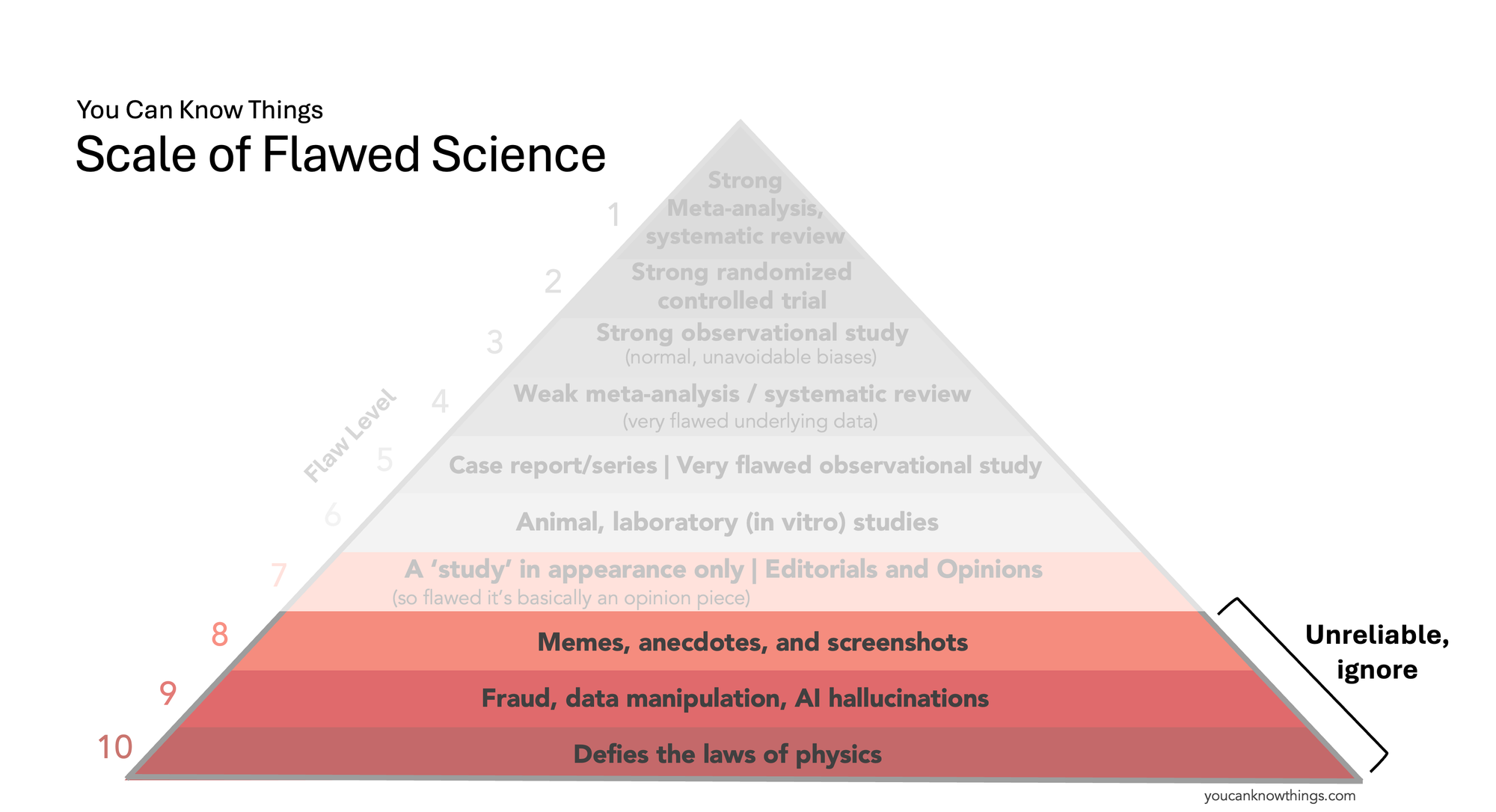
Flaw Level 8: Memes, anecdotes, and screenshots.
Short, simple stories are compelling – our brains are wired to believe them. But stories on the internet carry little scientific substance without valid citations or verifiable data. A story in the comment section about a life-changing supplement lacks scientific weight for two reasons: it’s an anecdote (a tiny, unverified snapshot that may not indicate a true causal effect or apply broadly) and it’s unverified (we don’t know if it’s accurate or if key medical details are missing). The effects of supplements should be studied, but carefully and systematically, not via vibes in the comments section.
Does this type of information give us reliable information we can use to make medical decisions? No, it's a tiny snapshot of information that may be inaccurate, incomplete, or not widely applicable.
Flaw Level 7: Editorials and opinions.
These are opinion pieces by experts (or non-experts) that discuss scientific topics without providing any new data. Their reliability varies: some cite strong evidence produced by others, while others cite weak data or no data at all. Because they present no original data and are often not peer-reviewed, they’re not considered to be strong scientific evidence (though the data they cite might be). An example includes this opinion piece by a single scientist arguing hydroxychloroquine was the key to defeating COVID, which cited many flaw level 5 (unreliable) studies.
In this section I also include a study in appearance only – a study that is so bad it's basically just an opinion piece, because the underlying data is extremely biased or unreliable for some other reason. Though they look like studies and may be peer-reviewed, their data are so unreliable they’re basically uninterpretable. An example includes this infamous, now retracted study of hydroxychloroquine for COVID.
Does this type of information give us reliable information we can use to make medical decisions? Uncertain, may be highly influenced by the author's individual bias, skill level, and quality of data cited (if any).
Flaw Level 6: Animal and laboratory studies.
Now we're getting into the standard hierarchy of evidence. Animal research and in vitro studies in a test tube provide important preliminary evidence about what treatments might work in humans, but most of them don't pan out. About 90% of drug candidates that show promise in these early experiments end up failing once they're tested in real human beings. They're important to figure out which candidates are worth the effort of a human clinical trial, but by themselves, they aren't given much weight when making treatment decisions about humans.
Does this type of information give us reliable information we can use to make medical decisions? Not really – just because it works in a dish doesn't meant it will work in a human.
Flaw Level 5: Case reports, case series and very flawed observational studies
Case reports and series are published, verified medical anecdotes. Clinicians write them to share interesting cases, such as unusual disease presentations or novel treatments with good outcomes. They are more reliable than medical anecdotes on the internet because they’re verified (written by clinicians and published in reputable journals) and include complete medical details (the doctors have access to the full medical record and patient history). But they are considered very preliminary evidence because they are still essentially anecdotes, and there is no control group.
Here I’ll deviate from the traditional pyramid to include very flawed observational studies at this level as well. There are multiple types of observational studies, but to make it simple, these studies typically 1. do have a control group* (they include people who didn't get the treatment under investigation) and 2. there is no randomization (treatment decisions happen organically in the hospital and are not directed by the researchers). These studies can be rigorous or deeply flawed depending on their design, sample size, similarity between the treatment and control groups, and how well the researchers controlled for any differences. "Very flawed" observational studies fail on multiple fronts to the point where their data isn't much more useful than anecdotes, such as this poorly designed study comparing COVID infections and vaccination rates.
Does this type of information give us reliable information we can use to make medical decisions? Not really, it is preliminary and may be unreliable.
*There are a few types of observational studies that don't have a control group, but that's more detail than we need to get into here.
Flaw Level 4: Weak meta-analysis and systematic reviews.
Systematic reviews and meta-analyses combine data from many studies on a single topic to see what the overall evidence shows. When they pull from strong underlying studies, they are super reliable, earning their spot on the top of the pyramid. But if the underlying studies are weak, fraudulent, or not applicable to the question under study, the results can be badly skewed, which is why I'm putting weak meta-analysis and systematic reviews down here at flaw level 4. Examples include this ivermectin meta-analysis which originally showed a benefit of ivermectin for COVID, a result that was driven primarily by a single study that was later found to be fraudulent. There are likely more examples like this that have not been discovered yet – check out the Medical Evidence Project, which aims to uncover fraudulent studies that distort systematic reviews and impact medical practice.
Does this type of information give us reliable information we can use to make medical decisions? Maybe, maybe not – if the underlying data quality is bad, it may be misleading us.
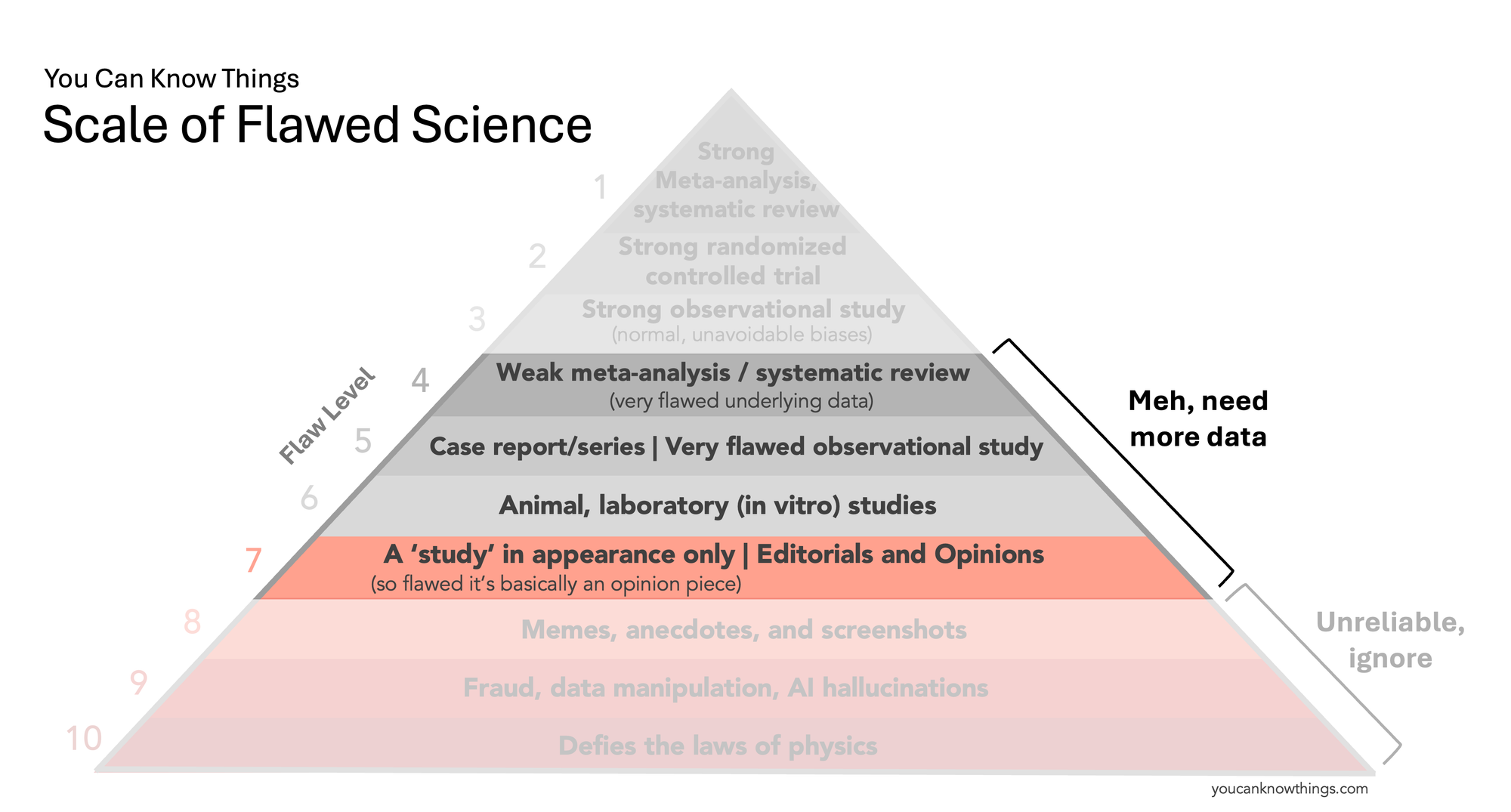
Flaw Level 3: Strong observational study
Now we're to the good studies. A strong observational study is all about the methods: a large enough sample, comparable treatment and control groups, appropriate statistical adjustments, and no weird or sketchy statistics. They’re still less reliable than randomized controlled trials because the researchers aren't controlling who gets the treatment, and statistical methods that account for differences between treatment and controls aren't perfect – a problem that randomization solves. But sometimes a randomized-controlled trial isn't feasible, and a good observational study is still pretty darn useful. High-quality examples include studies using national health registries (like this one in Denmark) that offer a comprehensive snapshot of the population and allow for detailed analysis.
Does this type of information give us reliable information we can use to make medical decisions? Yes – while there are still limitations, robust observational studies provide valuable information.
Flaw Level 2: Strong randomized controlled trial.
Well designed randomized controlled trials are the most reliable type of individual study we have. The process of randomization – where subjects are randomly assigned to get a treatment or control – minimizes differences between the groups, something observational studies can't do. But having the word "randomized" in the title does not automatically mean it's a good study: sample size, blinding, quality of randomization, follow-up duration, and statistical methods should still be scrutinized to determine if it's a "strong" RCT.
Does this type of information give us reliable information we can use to make medical decisions? Yes – this is the most robust type of individual study we have.
Flaw Level 1: Strong meta-analysis, systematic review
These meta-analyses and systematic reviews combine level 2 and 3 studies – strong observational studies and robust randomized controlled trials. No single study is perfect, but pooling data from multiple high-quality studies gives a much clearer overall picture, earning these studies their spot on the top of the pyramid.
Does this type of information give us reliable information we can use to make medical decisions? Yes – this is the highest quality of medical evidence we have.
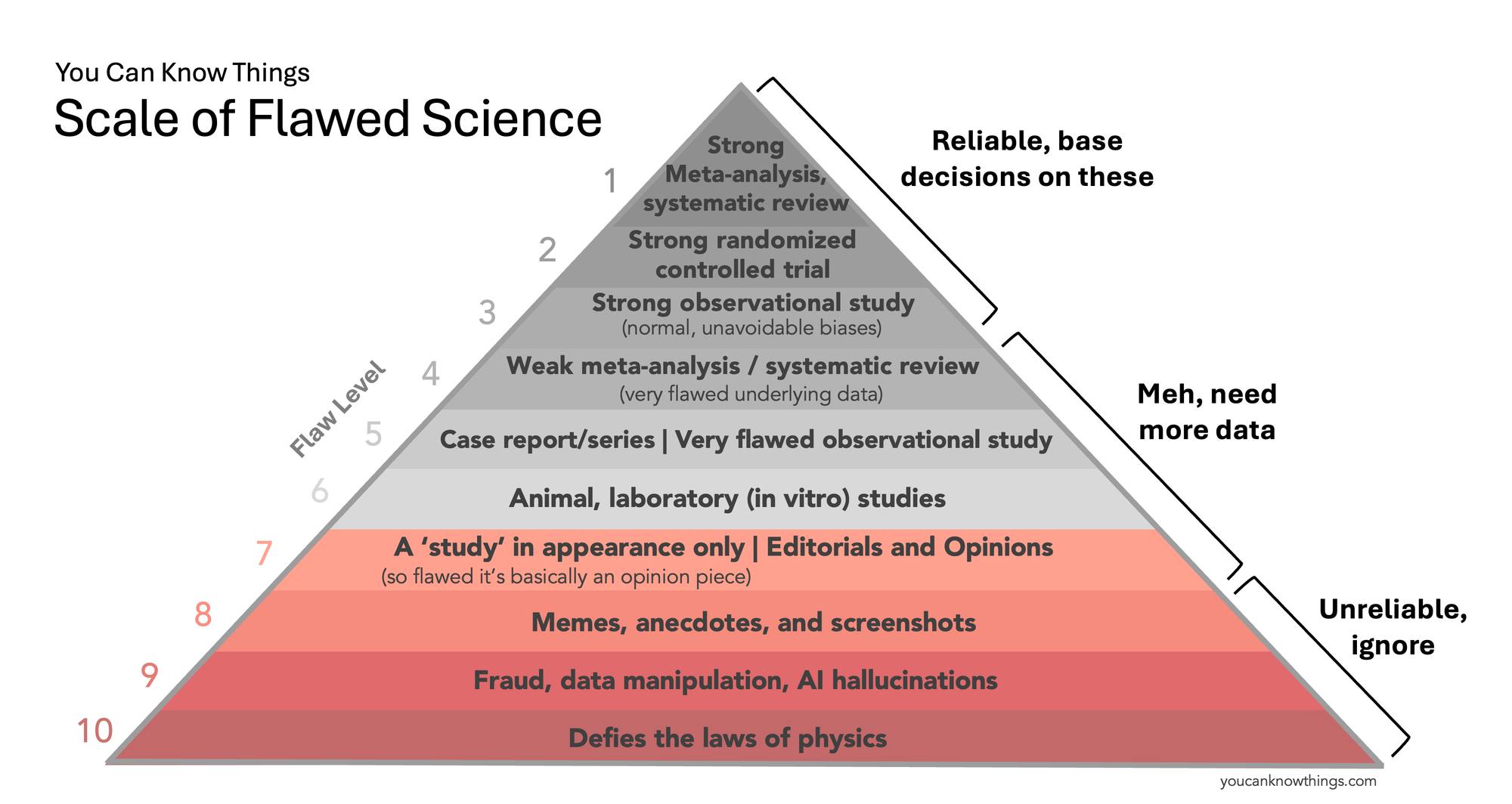
This scale isn't perfect – there are simplifications and assumptions, and there really should be a slot for poor quality RCTs and 'just ok' observational studies. But once a tool like this gets too complicated it's no longer useful for communicating, which is what this scale aims to do.
I hope you find it helpful.
Kristen Panthagani, MD, PhD, is completing a combined emergency medicine residency and research fellowship focusing on health literacy and communication. In her free time, she is the creator of the newsletter You Can Know Things and author of Your Local Epidemiologist’s section on Health (Mis)communication. You can subscribe to her website below or find her on Substack, Instagram, or Bluesky. Views expressed belong to KP, not her employer.